Non-Iterative Tuning Guide
Hello World
Let’s do a hybrid parameter tuning with grid search + random search, and run it distributedly
[1]:
def objective(a, b) -> float:
return a**2 + b**2
[2]:
from tune import Space, Grid, Rand, RandInt, Choice
space = Space(a=Grid(-1,0,1), b=Rand(-10,10)).sample(100, seed=0)
[4]:
from tune import suggest_for_noniterative_objective
result = suggest_for_noniterative_objective(objective, space, top_n=1)[0]
print(result.sort_metric, result)
NativeExecutionEngine doesn't respect num_partitions ROWCOUNT
0.1909396653178624 {'trial': {'trial_id': '58c94f4f-011e-53da-a85b-7e696ced6600', 'params': {'a': 0, 'b': 0.43696643500143395}, 'metadata': {}, 'keys': []}, 'metric': 0.1909396653178624, 'params': {'a': 0, 'b': 0.43696643500143395}, 'metadata': {}, 'cost': 1.0, 'rung': 0, 'sort_metric': 0.1909396653178624, 'log_time': datetime.datetime(2021, 10, 6, 23, 35, 53, 24547)}
Now run it distributedly, let’s use dask as as the example
[6]:
from fugue_dask import DaskExecutionEngine
result = suggest_for_noniterative_objective(
objective, space, top_n=1,
execution_engine = DaskExecutionEngine
)[0]
print(result.sort_metric, result)
0.1909396653178624 {'trial': {'trial_id': '58c94f4f-011e-53da-a85b-7e696ced6600', 'params': {'a': 0, 'b': 0.43696643500143395}, 'metadata': {}, 'keys': []}, 'metric': 0.1909396653178624, 'params': {'a': 0, 'b': 0.43696643500143395}, 'metadata': {}, 'cost': 1.0, 'rung': 0, 'sort_metric': 0.1909396653178624, 'log_time': datetime.datetime(2021, 10, 6, 23, 36, 16, 996725)}
In order to use tune in a more elegant and easier way, let’s firstly see how to configure the system.
Configuration
Configuring the system is not necessary but it has great benefit for simpifying your following works.
suggest_for_noniterative_objective and optimize_noniterative have a lot of parameters due to the complexity of tuning operations. But tune let you do global configuration so you don’t need to repeat the same configuration for every tuning task.
Customize Optimizer Converter
[7]:
from tune import TUNE_OBJECT_FACTORY
from tune import NonIterativeObjectiveLocalOptimizer
from tune_hyperopt import HyperoptLocalOptimizer
from tune_optuna import OptunaLocalOptimizer
import optuna
optuna.logging.disable_default_handler()
def to_optimizer(obj):
if isinstance(obj, NonIterativeObjectiveLocalOptimizer):
return obj
if obj is None or "hyperopt"==obj:
return HyperoptLocalOptimizer(max_iter=20, seed=0)
if "optuna" == obj:
return OptunaLocalOptimizer(max_iter=20)
raise NotImplementedError
# make default level 2 optimizer HyperoptLocalOptimizer, so you will not need to set again
TUNE_OBJECT_FACTORY.set_noniterative_local_optimizer_converter(to_optimizer)
Customize Monitor
Monitor is to collect and render information in real time, there are builtin monitors, you can also create your own.
[9]:
from typing import Optional
from tune import TUNE_OBJECT_FACTORY
from tune import Monitor
from tune_notebook import (
NotebookSimpleHist,
NotebookSimpleRungs,
NotebookSimpleTimeSeries,
PrintBest,
)
def to_monitor(obj) -> Optional[Monitor]:
if obj is None:
return None
if isinstance(obj, Monitor):
return obj
if isinstance(obj, str):
if obj == "hist":
return NotebookSimpleHist()
if obj == "rungs":
return NotebookSimpleRungs()
if obj == "ts":
return NotebookSimpleTimeSeries()
if obj == "text":
return PrintBest()
raise NotImplementedError(obj)
TUNE_OBJECT_FACTORY.set_monitor_converter(to_monitor)
Set Temp Path For Tuning
Temp path can be used to store serialized partitions or checkpoints. Most top level API usage requires a valid temporary path. We can use factory method to set a global value.
Notice if you want to tune distributedly, you should set the path to a distributed file system, for example s3.
[10]:
TUNE_OBJECT_FACTORY.set_temp_path("/tmp")
Tuning Examples
Sometimes, your objective function requires a input dataframe. There are two ways to use dataframes in general:
Pros |
Cons |
|
|---|---|---|
Take them as real dataframes, for example pandas dataframes. |
Simple and intuitive |
Either the datas ize can’t scale or you have to couple with a distributed solution such as Spark |
Take them from parameters, for example paths as parameters. |
You have the full control how and when and whether to load the data. More scalable. |
More code to make it work |
In general, the second way is a better idea. But if your case can fit in the first scenario, then tune has a simple solution letting you take the pandas dataframes as input.
[11]:
from sklearn.datasets import load_diabetes
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import RandomForestRegressor
import pandas as pd
import numpy as np
diabetes = load_diabetes(as_frame=True)["frame"]
def evaluate(train_df:pd.DataFrame, **kwargs) -> float:
x, y = train_df.drop("target", axis=1), train_df["target"]
model = RandomForestRegressor(**kwargs)
# pay attention here, score is larger better so we return the negative value
return -np.mean(cross_val_score(model, x, y, scoring="neg_mean_absolute_error", cv=4))
evaluate(diabetes)
[11]:
46.646344389844394
With the given diabetes dataset and the objective function evaluate let’s tune it in different ways
Hybrid Tuning
[13]:
# Grid search only
space = Space(n_estimators=Grid(100,200), random_state=0)
result = suggest_for_noniterative_objective(
evaluate, space, top_n=1,
df = diabetes, df_name = "train_df"
)[0]
print(result.sort_metric, result)
NativeExecutionEngine doesn't respect num_partitions ROWCOUNT
46.63103787878788 {'trial': {'trial_id': '5d719fa7-9537-58b1-86cd-fa69a4e75272', 'params': {'n_estimators': 100, 'random_state': 0}, 'metadata': {}, 'keys': []}, 'metric': 46.63103787878788, 'params': {'n_estimators': 100, 'random_state': 0}, 'metadata': {}, 'cost': 1.0, 'rung': 0, 'sort_metric': 46.63103787878788, 'log_time': datetime.datetime(2021, 10, 6, 23, 37, 11, 450017)}
[14]:
# grid + random
space = Space(n_estimators=Grid(100,200), max_depth=RandInt(2,10), random_state=0).sample(3, seed=0)
result = suggest_for_noniterative_objective(
evaluate, space, top_n=1,
df = diabetes, df_name = "train_df"
)[0]
print(result.sort_metric, result)
NativeExecutionEngine doesn't respect num_partitions ROWCOUNT
46.52677715635581 {'trial': {'trial_id': '0a53519f-576b-5a9f-8ef9-4a7e7f69de1a', 'params': {'n_estimators': 200, 'max_depth': 6, 'random_state': 0}, 'metadata': {}, 'keys': []}, 'metric': 46.52677715635581, 'params': {'n_estimators': 200, 'max_depth': 6, 'random_state': 0}, 'metadata': {}, 'cost': 1.0, 'rung': 0, 'sort_metric': 46.52677715635581, 'log_time': datetime.datetime(2021, 10, 6, 23, 37, 26, 492058)}
[16]:
# random + bayesian optimization (hyperopt is used by default)
space = Space(n_estimators=RandInt(50,200))* Space(max_depth=RandInt(2,10), random_state=0).sample(2, seed=0)
result = suggest_for_noniterative_objective(
evaluate, space, top_n=1,
df = diabetes, df_name = "train_df"
)[0]
print(result.sort_metric, result)
result = suggest_for_noniterative_objective(
evaluate, space, top_n=1,
df = diabetes, df_name = "train_df",
local_optimizer="optuna" # switch to optuna for bayesian optimization
)[0]
print(result.sort_metric, result)
NativeExecutionEngine doesn't respect num_partitions ROWCOUNT
NativeExecutionEngine doesn't respect num_partitions ROWCOUNT
46.419699856089416 {'trial': {'trial_id': '52919031-4f17-58d2-8cfc-e4a1d0e4555a', 'params': {'n_estimators': 175, 'max_depth': 6, 'random_state': 0}, 'metadata': {}, 'keys': []}, 'metric': 46.419699856089416, 'params': {'n_estimators': 175, 'max_depth': 6, 'random_state': 0}, 'metadata': {}, 'cost': 1.0, 'rung': 0, 'sort_metric': 46.419699856089416, 'log_time': datetime.datetime(2021, 10, 6, 23, 38, 37, 355059)}
46.41622613826187 {'trial': {'trial_id': '52919031-4f17-58d2-8cfc-e4a1d0e4555a', 'params': {'n_estimators': 176, 'max_depth': 6, 'random_state': 0}, 'metadata': {}, 'keys': []}, 'metric': 46.41622613826187, 'params': {'n_estimators': 176, 'max_depth': 6, 'random_state': 0}, 'metadata': {}, 'cost': 1.0, 'rung': 0, 'sort_metric': 46.41622613826187, 'log_time': datetime.datetime(2021, 10, 6, 23, 39, 9, 442020)}
Partition And Train And Tune
This is a very important feature of tune. Sometimes, partitioning the data and train and tune small independent models separately can generate better result. This is not necessarily true, but at least we make it very simple for you to try. You only need to specify partition_keys. And with a distributed engine, all independent tasks are fully parallelized.
[17]:
space = Space(n_estimators=Grid(50,200), max_depth=RandInt(2,10), random_state=0).sample(2, seed=0)
result = suggest_for_noniterative_objective(
evaluate, space, top_n=1,
df = diabetes, df_name = "train_df",
partition_keys = ["sex"] # for male and females, we train and tune separately
)
for r in result:
print(r.trial.keys, r.sort_metric, r)
NativeExecutionEngine doesn't respect num_partitions ROWCOUNT
[0.0506801187398187] 42.48208345425722 {'trial': {'trial_id': '83f593dd-a3a2-5ac0-b389-ee19f8cc1134', 'params': {'n_estimators': 200, 'max_depth': 8, 'random_state': 0}, 'metadata': {}, 'keys': [0.0506801187398187]}, 'metric': 42.48208345425722, 'params': {'n_estimators': 200, 'max_depth': 8, 'random_state': 0}, 'metadata': {}, 'cost': 1.0, 'rung': 0, 'sort_metric': 42.48208345425722, 'log_time': datetime.datetime(2021, 10, 6, 23, 40, 38, 579320)}
[-0.044641636506989] 46.66399292343497 {'trial': {'trial_id': '1759366d-de55-5418-b1b5-48cf91f529a0', 'params': {'n_estimators': 50, 'max_depth': 8, 'random_state': 0}, 'metadata': {}, 'keys': [-0.044641636506989]}, 'metric': 46.66399292343497, 'params': {'n_estimators': 50, 'max_depth': 8, 'random_state': 0}, 'metadata': {}, 'cost': 1.0, 'rung': 0, 'sort_metric': 46.66399292343497, 'log_time': datetime.datetime(2021, 10, 6, 23, 40, 33, 356186)}
Distributed Tuning
tune is based on Fugue so it can run seamlessly using all Fugue supported execution engines and in the same way Fugue uses them.
[18]:
# This space is a combination of grid and random search
# all level 1 searches, so it can be fully distributed
space = Space(n_estimators=Grid(50,200), max_depth=RandInt(2,10), random_state=0).sample(2, seed=0)
result = suggest_for_noniterative_objective(
evaluate, space, top_n=1,
df = diabetes, df_name = "train_df",
partition_keys = ["sex"],
execution_engine = DaskExecutionEngine # this makes the tuning process distributed
)
for r in result:
print(r.trial.keys, r.sort_metric, r)
[0.0506801187398187] 42.79742975473356 {'trial': {'trial_id': '0f2053de-71b2-514d-b4ff-8495b93a042b', 'params': {'n_estimators': 200, 'max_depth': 6, 'random_state': 0}, 'metadata': {}, 'keys': [0.0506801187398187]}, 'metric': 42.79742975473356, 'params': {'n_estimators': 200, 'max_depth': 6, 'random_state': 0}, 'metadata': {}, 'cost': 1.0, 'rung': 0, 'sort_metric': 42.79742975473356, 'log_time': datetime.datetime(2021, 10, 6, 23, 40, 57, 795165)}
[-0.044641636506989] 47.480845528260254 {'trial': {'trial_id': '46da77b5-089d-57b9-8036-0ca2e3646fdb', 'params': {'n_estimators': 200, 'max_depth': 6, 'random_state': 0}, 'metadata': {}, 'keys': [-0.044641636506989]}, 'metric': 47.480845528260254, 'params': {'n_estimators': 200, 'max_depth': 6, 'random_state': 0}, 'metadata': {}, 'cost': 1.0, 'rung': 0, 'sort_metric': 47.480845528260254, 'log_time': datetime.datetime(2021, 10, 6, 23, 41, 0, 714602)}
Realtime Monitoring
Fugue framework can let workers communicate with driver in realtime (see this). So tune leverages this feature for monitoring and iterative problems.
[19]:
space = Space(n_estimators=RandInt(1,20), max_depth=RandInt(2,10), random_state=0).sample(100, seed=0)
result = suggest_for_noniterative_objective(
evaluate, space, top_n=1,
df = diabetes, df_name = "train_df",
monitor="ts"
)
for r in result:
print(r.trial.keys, r.sort_metric, r)

[] 46.84555314021837 {'trial': {'trial_id': '2c9456ad-f8a7-56df-9195-3266ffabd941', 'params': {'n_estimators': 20, 'max_depth': 3, 'random_state': 0}, 'metadata': {}, 'keys': []}, 'metric': 46.84555314021837, 'params': {'n_estimators': 20, 'max_depth': 3, 'random_state': 0}, 'metadata': {}, 'cost': 1.0, 'rung': 0, 'sort_metric': 46.84555314021837, 'log_time': datetime.datetime(2021, 10, 6, 23, 41, 19, 488640)}
[] 46.84555314021837 {'trial': {'trial_id': '2c9456ad-f8a7-56df-9195-3266ffabd941', 'params': {'n_estimators': 20, 'max_depth': 3, 'random_state': 0}, 'metadata': {}, 'keys': []}, 'metric': 46.84555314021837, 'params': {'n_estimators': 20, 'max_depth': 3, 'random_state': 0}, 'metadata': {}, 'cost': 1.0, 'rung': 0, 'sort_metric': 46.84555314021837, 'log_time': datetime.datetime(2021, 10, 6, 23, 41, 23, 761028)}
To enable monitoring on a distributed engine, you must also enable remote call back. Without shortcut, you have to set multiple configs. Here is an example with the fuggle package who sets the shortcuts for callbacks on Kaggle, it’s as simple as one config: callback: True
[20]:
space = Space(n_estimators=RandInt(1,20), max_depth=RandInt(2,10), random_state=0, n_jobs=1).sample(200, seed=0)
callback_conf = {
"fugue.rpc.server": "fugue.rpc.flask.FlaskRPCServer",
"fugue.rpc.flask_server.host": "0.0.0.0",
"fugue.rpc.flask_server.port": "1234",
"fugue.rpc.flask_server.timeout": "2 sec",
}
result = suggest_for_noniterative_objective(
evaluate, space, top_n=1,
df = diabetes, df_name = "train_df",
monitor="ts",
execution_engine = DaskExecutionEngine,
execution_engine_conf=callback_conf
)
for r in result:
print(r.trial.keys, r.sort_metric, r)

[] 46.89339381813802 {'trial': {'trial_id': 'af51195c-3da6-59e5-a4ab-9802041ab314', 'params': {'n_estimators': 20, 'max_depth': 5, 'random_state': 0, 'n_jobs': 1}, 'metadata': {}, 'keys': []}, 'metric': 46.89339381813802, 'params': {'n_estimators': 20, 'max_depth': 5, 'random_state': 0, 'n_jobs': 1}, 'metadata': {}, 'cost': 1.0, 'rung': 0, 'sort_metric': 46.89339381813802, 'log_time': datetime.datetime(2021, 10, 6, 23, 42, 0, 265059)}
[] 46.89339381813802 {'trial': {'trial_id': 'af51195c-3da6-59e5-a4ab-9802041ab314', 'params': {'n_estimators': 20, 'max_depth': 5, 'random_state': 0, 'n_jobs': 1}, 'metadata': {}, 'keys': []}, 'metric': 46.89339381813802, 'params': {'n_estimators': 20, 'max_depth': 5, 'random_state': 0, 'n_jobs': 1}, 'metadata': {}, 'cost': 1.0, 'rung': 0, 'sort_metric': 46.89339381813802, 'log_time': datetime.datetime(2021, 10, 6, 23, 42, 0, 265059)}
For the shortcuts of monitoring
tsto monitor the up-to-date best metric collectedhistto motitor the histogram of metrics collected
Early Stopping
When you enable monitoring, you often see the curve flattens quickly, so it can save significant time if it can stop trying the remaining trials. To do early stopping, it is required to enable callbacks for distributed engine (for monitoring, if you don’t monitor, you don’t need to enable callback).
In tune, you can also combine stoppers with logical operators
[21]:
from tune import small_improvement, n_updates
space = Space(n_estimators=RandInt(1,20), max_depth=RandInt(2,10), random_state=0, n_jobs=1).sample(200, seed=0)
callback_conf = {
"fugue.rpc.server": "fugue.rpc.flask.FlaskRPCServer",
"fugue.rpc.flask_server.host": "0.0.0.0",
"fugue.rpc.flask_server.port": "1234",
"fugue.rpc.flask_server.timeout": "2 sec",
}
result = suggest_for_noniterative_objective(
evaluate, space, top_n=1,
df = diabetes, df_name = "train_df",
monitor="ts",
# stop if at least 5 updates on best
# AND the last update on best improved less than 0.1 (abs value)
stopper= n_updates(5) & small_improvement(0.1,1),
execution_engine = DaskExecutionEngine,
execution_engine_conf=callback_conf
)
for r in result:
print(r.trial.keys, r.sort_metric, r)
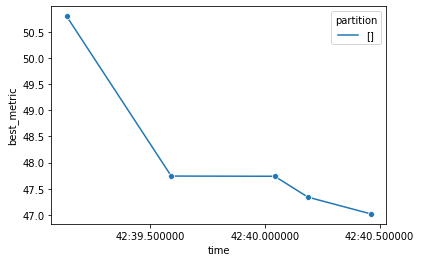
[] 47.01773216903467 {'trial': {'trial_id': 'f84ce5f5-207b-5ab7-a81a-be80879d5431', 'params': {'n_estimators': 19, 'max_depth': 4, 'random_state': 0, 'n_jobs': 1}, 'metadata': {}, 'keys': []}, 'metric': 47.01773216903467, 'params': {'n_estimators': 19, 'max_depth': 4, 'random_state': 0, 'n_jobs': 1}, 'metadata': {}, 'cost': 1.0, 'rung': 0, 'sort_metric': 47.01773216903467, 'log_time': datetime.datetime(2021, 10, 6, 23, 42, 40, 406040)}
[] 47.01773216903467 {'trial': {'trial_id': 'f84ce5f5-207b-5ab7-a81a-be80879d5431', 'params': {'n_estimators': 19, 'max_depth': 4, 'random_state': 0, 'n_jobs': 1}, 'metadata': {}, 'keys': []}, 'metric': 47.01773216903467, 'params': {'n_estimators': 19, 'max_depth': 4, 'random_state': 0, 'n_jobs': 1}, 'metadata': {}, 'cost': 1.0, 'rung': 0, 'sort_metric': 47.01773216903467, 'log_time': datetime.datetime(2021, 10, 6, 23, 42, 40, 406040)}
The above example combined a warmup period n_updates(5) and improvement check small_improvement(0.1,1) so it does not stop too early or too late.
You can also customize a simple stopper
[22]:
from typing import List
from tune.noniterative.stopper import SimpleNonIterativeStopper
from tune import TrialReport
def less_than(v: float) -> SimpleNonIterativeStopper:
def func(current: TrialReport, updated: bool, reports: List[TrialReport]):
return current.sort_metric <= v
return SimpleNonIterativeStopper(func, log_best_only=True)
[23]:
result = suggest_for_noniterative_objective(
evaluate, space, top_n=1,
df = diabetes, df_name = "train_df",
monitor="ts",
stopper= less_than(49),
execution_engine = DaskExecutionEngine,
execution_engine_conf=callback_conf
)
for r in result:
print(r.trial.keys, r.sort_metric, r)
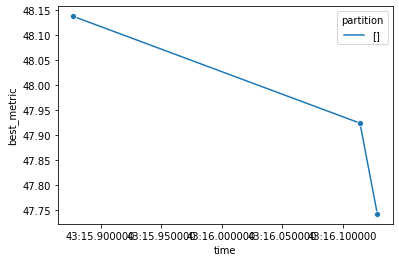
[] 47.74170052753941 {'trial': {'trial_id': 'b9ab0d11-991d-53d2-ad41-246dcbe23c22', 'params': {'n_estimators': 17, 'max_depth': 2, 'random_state': 0, 'n_jobs': 1}, 'metadata': {}, 'keys': []}, 'metric': 47.74170052753941, 'params': {'n_estimators': 17, 'max_depth': 2, 'random_state': 0, 'n_jobs': 1}, 'metadata': {}, 'cost': 1.0, 'rung': 0, 'sort_metric': 47.74170052753941, 'log_time': datetime.datetime(2021, 10, 6, 23, 43, 15, 891806)}
[] 47.74170052753941 {'trial': {'trial_id': 'b9ab0d11-991d-53d2-ad41-246dcbe23c22', 'params': {'n_estimators': 17, 'max_depth': 2, 'random_state': 0, 'n_jobs': 1}, 'metadata': {}, 'keys': []}, 'metric': 47.74170052753941, 'params': {'n_estimators': 17, 'max_depth': 2, 'random_state': 0, 'n_jobs': 1}, 'metadata': {}, 'cost': 1.0, 'rung': 0, 'sort_metric': 47.74170052753941, 'log_time': datetime.datetime(2021, 10, 6, 23, 43, 15, 891806)}
The stopper will try to do graceful stop, so after the stop criteria, some running trials may still finish in with a distributed engine and report back, that is normal. If you want to stop faster, for example set: stop_check_interval: "5sec". But if you have a lot of workers, the frequent check may be a burden on the driver side, it also depends on how heavy compute your custom stopper is using.
Notice: You must create new stoppers everytime you call suggest_for_noniterative_objective because SimpleNonIterativeStopper is stateful.
[ ]: